AAAI 人工智能会议(AAAI Conference on Artificial Intelligence)由国际先进人工智能协会主办,是人工智能领域的顶级国际学术会议之一。第40届AAAI人工智能会议将于2026年1月20日至1月27日在新加坡召开。本届大会共收到23,680份有效投稿,最终接收论文4,167篇,录用率为17.6%。数字取证教育部工程研究中心师生共有3篇论文入选,具体研究内容如下,欢迎交流探讨。
1、Sim-to-Real: An Unsupervised Noise Layer for Screen-Camera Watermarking Robustness
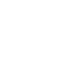
随着屏显翻拍、屏摄盗录、打印拍摄等侵权手段的出现,数字媒体作品盗版呈现隐匿强、传播快、溯源难的特点。与传统攻击相比,屏幕拍摄会产生更复杂、更耦合的变形,包括:透视畸变、光照变化、摩尔纹、传感器噪声、镜头模糊等。这些畸变往往相互叠加,而且具有强非线性特征,现有可微噪声模拟无法真实反映屏摄噪声模式的复杂性,导致训练出的模型对真实屏摄鲁棒性不足。为了应对屏幕拍摄时所产生的图像失真,在模型训练期间,现有方法常常使用在编码器和解码器之间应用可微图像扰动来近似由屏幕拍摄引起的噪声,常用的方案如下图所示。
数学建模能灵活近似屏摄噪声并解析各分量影响。但其常假设噪声独立且线性叠加,忽略了真实噪声源的耦合,导致偏差;同时难以捕捉细粒度局部失真。神经网络能拟合非线性屏摄噪声,但严重依赖高质量配对数据,而数据采集过程费力且易错。此外,模型易被复杂噪声淹没,难以收敛,且可能忽略细节特征。本文提出模拟到真实(S2R)框架。该框架首先生成基于数学模型的粗糙噪声表示,并利用无监督学习在未配对数据上对其进行细化,从而结合二者优势。在训练阶段,在给定一组干净图像xs和真实的屏摄图像yu的情况下,首先使用真实屏幕拍摄图像yu的数学建模变换T将干净图像变换成具有已知模拟噪声分布图像yc,通过无监督训练,图转图网络G逐渐调整yc以匹配yu的分布,最终输出近似图像yu。在验证阶段,给定干净图像xs,经过变换T和网络G后,最终输出为yu out。最终,S2R在不同拍摄角度与距离的真实屏摄实验中均取得最低BER,尤其在0°–40°和20–40 cm的主流使用区间内稳定保持低误码率,相比其他方案均有显著提升,验证了S2R所带来的鲁棒性优势。此外,借助残差缩放策略,S2R在128×128到1080×1920的多分辨率场景中仍保持高PSNR、高SSIM和低BER,充分证明了该框架在真实部署中的可扩展性与泛化适应能力。
论文作者:
吴宇峰,廖鑫,王保卫,方涵,武晓帅,陈明月,王桂玲
Radar-APLANC: Unsupervised Radar-based Heartbeat Sensing via Augmented Pseudo-Label and Noise Contrast
在日常生活中,测心率的方式已经非常丰富:可穿戴手环、智能手表、手机摄像头的远程光体积描记(rPPG),以及医疗级 ECG、PPG 设备等。然而这些方式要么需要紧贴皮肤、持续佩戴,要么对光照和隐私敏感,要么设备复杂、成本较高。毫米波 / FMCW 雷达因为可以无接触、隔空捕捉到胸部亚毫米级的位移,被认为是新一代无接触生命体征感知的重要技术路线之一。只要在环境中放置一块雷达,就有机会稳定感知被测者的呼吸和心搏,为家庭监护、智能家居、睡眠监测等应用提供更自然的交互方式。但现实中,雷达心率测量仍然面临两大瓶颈:一是传统信号处理方法对噪声非常敏感,轻微的身体晃动、多径反射、低信噪比等都会让相位展开和滤波后的心搏波形变形;二是近年来效果很好的深度学习方法大多依赖大规模、严格同步的 PPG / ECG 标签,采集成本高、扩展到新场景和新人群非常困难。
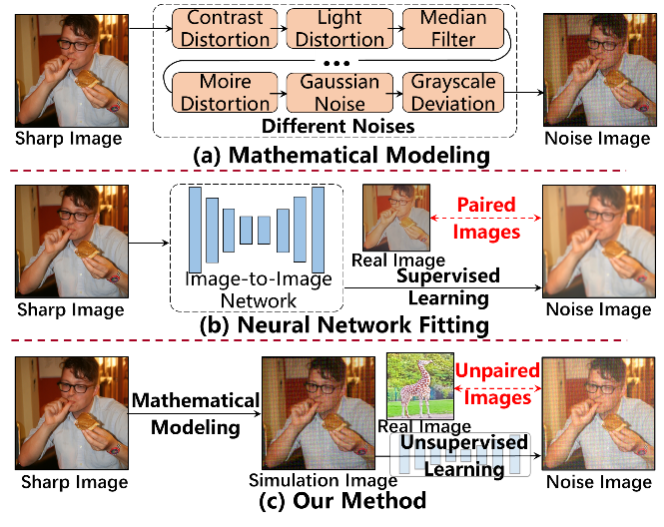
为此,本文提出了一个全新的无监督雷达心率感知框架 Radar-APLANC(Augmented Pseudo-Label and Noise Contrast),在完全不使用 PPG / ECG 等生理标签的前提下,让模型仅凭雷达数据就学会区分“心率信号”和“环境噪声”,并最终输出高质量的心搏波形和准确的心率估计。在 Radar-APLANC 中,不再把噪声当成“需要被过滤掉的垃圾”,也不把传统信号处理方法当成“落后的 baseline”。相反,将噪声显式地引入训练过程,作为对比学习中的负样本;同时,把传统方法产生的心率信号视作伪标签,通过精心设计的伪标签增强机制,从中筛选出对模型最有帮助的高质量监督信号。本文框架采用两阶段训练策略:第一阶段通过噪声对比学习快速让网络“看得懂心搏长什么样”;第二阶段利用增强伪标签生成器,从多种候选心率中自适应挑选最靠谱的一条,对模型进行进一步精修。
本文所提方案实现流程图
论文作者:王颖,孙照东,程旭,何祖贤,李晓白
3、Towards Provably Secure and Highly Robust Generative Image SteganographyLeveraging Latent Diffusion Model
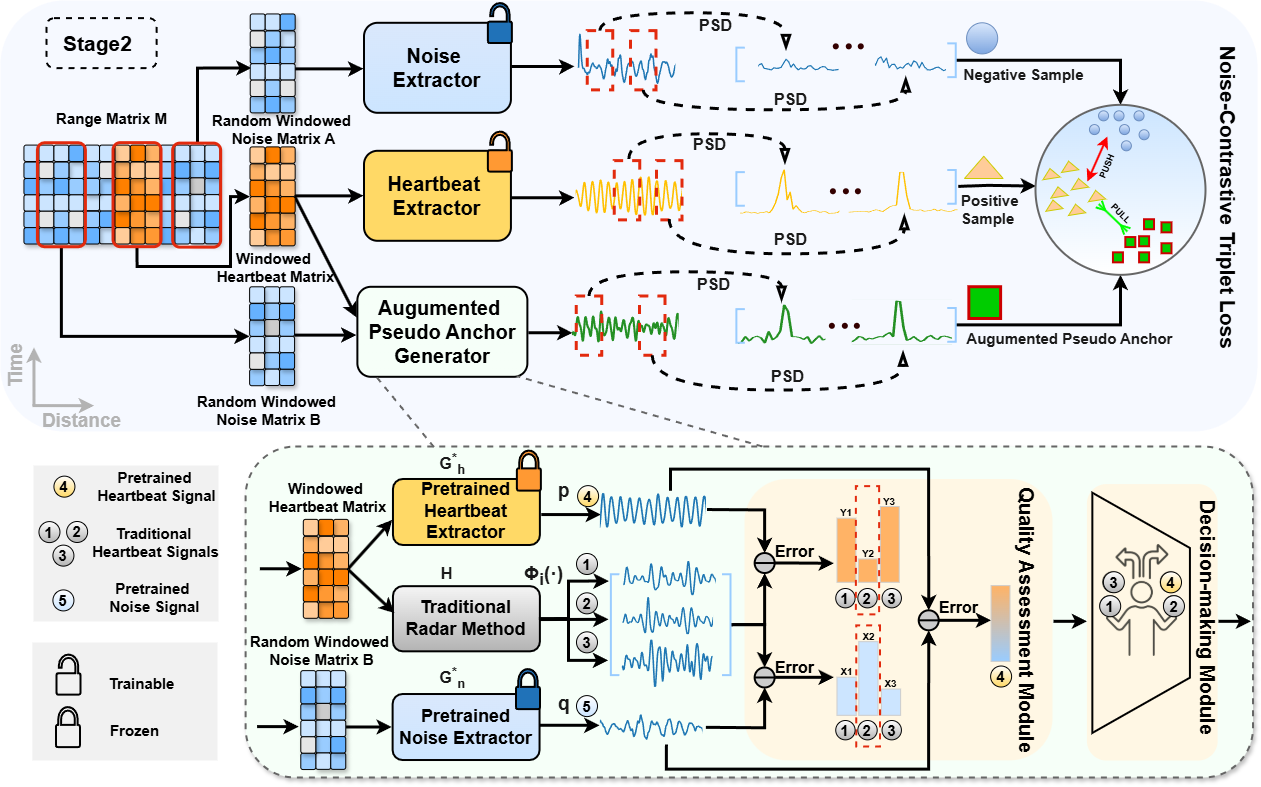
生成式图像隐写术是一种在生成模型生成图像的过程中隐藏秘密信息的技术。早期,人们使用生成对抗网络等生成模型来实现图像隐写任务,然而由于模型本身的限制,往往不能生成高质量的图像。近年来,扩散模型因其卓越的生成能力备受人们关注,研究者通过某种隐写算法将秘密信息隐藏到潜在向量中,进而将向量输入到扩散模型以生成隐写图像。但是目前存在的隐写算法往往会扭曲潜在向量的分布,导致生成的图像视觉质量偏低,容易引起第三方的怀疑,缺乏可证明的安全性。同时隐写图像经有损信道传输后无法以较高的准确率提取出秘密信息,鲁棒性较差,难以应用于现实场景。为了解决以上问题,本文提出了一种利用潜在扩散模型的新型隐写框架。首先通过主动探索潜在扩散模型的天然鲁棒性,得出一个一致性结论:图像在经受攻击后,其被扩散模型编码成的潜在向量中的符号基本上保持不变。基于这一发现,本文提出一种自适应分布保持机制,从而能够生成高质量的隐写图像,实现可证明安全。大量实验结果表明,所提方法在多种常见图像攻击下的鲁棒性表现均优于现有主流方法,同时在多种隐写分析工具的检测性表现出良好性能。
本文所提方案的框架图
论文作者:
袁程胜,冀昭楠,崔琦,周志立,李新亭,夏志华