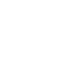
为了提高可听语音交互场景中的语音清晰度,双麦克风语音增强(SE)技术结合耳内麦克风和耳外麦克风,已引起研究界的广泛关注。然而,现有的双麦克风语音增强技术基于一个较强的假设:高质量的耳内语音(辅助模态)能够为目标空气传播语音(主要模态)提供有效的补充信息,这降低了其在实际应用中的适应性。在我们的工作中,我们探索了一个关键现象:耳道变形(ECD)引起的气压不平衡会对耳内语音的质量产生不利影响,进而导致语音增强性能显著下降,如图1所示。
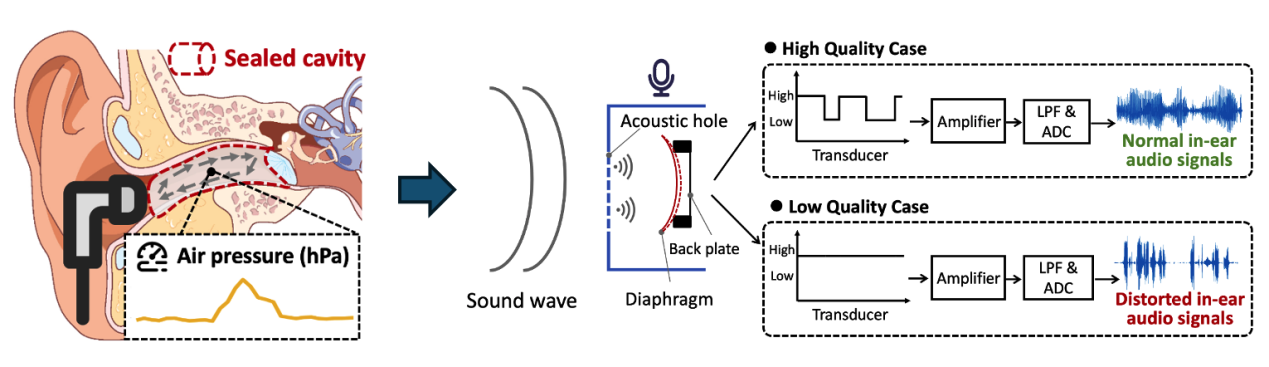
图1 耳道变形(ECD)导致耳内语音的质量下降
为了解决这一瓶颈问题,我们设计了一种高效的、质量感知的语音增强方案,名为QuaSE,它通过评估耳内语音的质量变化,高效且动态地融合补充信息。此外,基于对ECD引起的频谱失真的分析,我们设计了一种包含质量感知数据选择和内容感知增强的训练策略,以提高QuaSE的泛化能力。系统整体流程图如图2所示。大量实验表明,QuaSE在PESQ、STOI、SI-SDR和SegSNR四个指标上分别比现有最佳技术提高了6.27%、4.54%、14.90%和11.93%。此外,我们还验证了所提出的质量感知融合策略可以模块化地集成到其他感知任务中,从而提高融合性能。
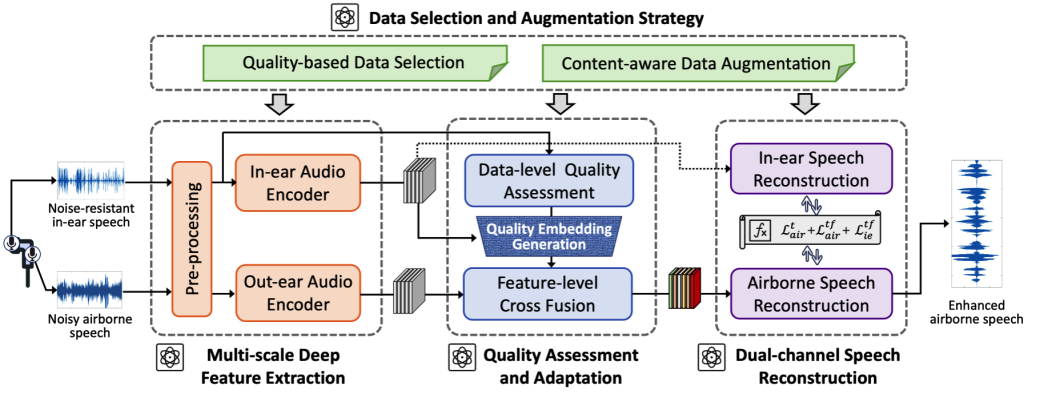
图2 QuaSE整体框架
为了评估我们方案的整体性能,我们与几种方案进行了基线比较,包括 Phasen 、Inter-Subnet、ClearSpeech 和 EarSpeech。其中,Phasen和InterSubnet 是典型的基于单模态的语音增强方案。ClearSpeech和 EarSpeech是目前最先进的双麦克风语音增强方案,它们结合了入耳式和出耳式麦克风。为了确保比较的公平性,我们仅复现了这些方案的模型。如表1所示。QuaSE在PESQ、STOI、SI-SDR和SegSNR指标上分别比最佳基线模型提升了9.35%、4.55%、17.68%和 12.89%。与ClearSpeech和EarSpeech相比,QuaSE的显著改进主要在于其能够通过动态融合基于质量变化的互补信息,有效解决低质量耳内语音对空中语音增强的负面影响。
表 1 不同噪声条件下的语音增强指标。
相关论文已被ACM IMWUT 2026录用,该论文是多家国内外高校共同合作完成,包括韩飞宇(副教授、南京信息工程大学),闫大伟(校聘教授、河北大学)、王山岳(博士后研究员、香港理工大学)、黄锦阳(副教授、合肥工业大学)、冯元浩(博士后研究员、日本电气通信大学)和杨盘隆(教授、南京信息工程大学)。ACM IMWUT是国际普适计算领域顶刊,属于中国计算机学会(CCF)推荐的A类国际学术会议/期刊,团队将在今年10月份的ACM UbiComp国际大会上进行宣讲交流。
论文第一作者为南京信息工程大学韩飞宇,副教授,工学博士。2024年6月于中国科学技术大学取得工学博士学位,2019年6月于南京理工大学取得学士学位,主要研究方向为智能物联网(AIoT)、多模态智能、无线感知、移动计算、具身智能等。在智能物联网领域的顶级会议和期刊上发表多篇学术成果,其中包括ACM Ubicomp/IMWUT、ACM MobiSys、IEEE TMC、IEEE JSAC、IEEE INFOCOM等。作为项目负责人主持国家青年基金,江苏省青年基金,江苏省高等学校自然科学研究面上项目等多项项目,参与国家基金委重点项目、中科院重点先导等项目。